
Component-based Software Design
Lessons from physical systems
Software systems are difficult to design because code does not delineate and organize itself. Even experienced engineers can struggle to design a system because there are many solutions but it’s not clear which is the best. Compounding the difficulty: engineers know that code can work fine even if, internally, it’s an unorganized highly-entangled mess. We want code to be well-organized, but we don’t know how to make it so. Component-based design is the solution.
The goal of this blog post is to change the way you think about, design, and implement software. Component-based design (CBD) is the solution, and thinking in CBD terms has two results: it makes it easier to design software, and it produces better software.
CBD makes it easier to design software because you are already steeped in component-based design: most (perhaps all?) physical and biological systems are component-based. In your body, organs are components. How many can you name and say what they do? Biological systems are too complex for a blog post, so instead we will look at refrigerators, cars, and light bulbs.
CBD produces better software because it breaks down large problems into smaller problems. The smaller the scope, the easier it is to program correctly and bug-free. Small, well-written components are the foundation of large, well-designed systems.
Before we look at refrigerators, let’s state more clearly what we mean by a “well-designed software system”.
Well-designed Software System
What makes software systems well-designed? From a high level, what are the aspects and principles that we recognize in well-designed systems? Here’s my list:
- Delineation: Components are delineated and align “at the seams”
- Identity: Each component has a clear and unified purpose
- Flow: Can follow code flow at high and low levels
- Language: Consistent terminology, domain language, etc.
- Testing: Thorough unit testing with high (>70%) test coverage
- Comments: Succinct yet thorough code comments
- Patterns: Evidence of software patterns and reuse
- Boring: At low level or small scope, code is so easy to understand it’s boring
- NS: Code at every level is necessary and sufficient
When a software systems exhibits those points, it is difficult not to be well-designed. Points 1-4 motivate a well-designed system from the top down, i.e. from the level of design down to the choice and implementation of components. Points 1 and 2 are the most important; we’ll see why later in this section. Points 5-8 motivate a well-designed system from the bottom up, i.e. from the level of actual code up to their intended design and implementation within a component. Point 9 applies globally: every component should be necessary and sufficient, and every line of code within every component should be necessary and sufficient.
In my experience, no engineer would disagree with those points. But to illustrate them further, consider their opposites:
- Components overlap, difficult to tell them apart
- Components do many different, unrelated things
- Difficult to follow a basic request from start to finish
- Little to no unit tests, or poor test coverage
- Concepts are called different things in different code
- What comments? Or worse: comment are wrong or misleading
- All solutions bespoke, all wheels reinvented
- A single function is difficult to understand
- Unnecessary or duplicate code and logic
Sound familiar? We’ve all seen code that exemplifies the second list. It is difficult for a system to be well-designed if exhibiting too many of those counterpoints.
Delineation and Identity are the most important aspects of a well-designed system because they define components. What is a component of any system if not separate (delineated) and identifiable? This sounds trivially true, but in software it is very often not true. To illustrate this further, imagine how a human body might be implemented in software. An engineer might design the heart and liver as a single component by reasoning that, since blood passes through both as a necessary part of their function, they are a “blood processing” component:
package blood
type Processor interface {
Pump(rate float64) error
Detoxify() error
}
That is a delineated component, so it’s a good start, but its identity is conflated. The identify of a component is its single responsibility. To test identity, try to answer the question “What does it do?” in a single sentence that accurately and completely captures its high-level responsibility. For blood.Processor, saying, “It processes blood.”, is neither accurate nor complete because “processes” is too vague. In software, most components “process”, “store”, “transfer”, “calculate”, and other generic computing terms. These are not always bad design, but they should be thoroughly scrutinized by the team to see if a generically-named component is really several specific components. Let’s further this example by adding to blood.Processor another method: Oxygenate() error. The lungs oxygenate blood. This is a type of processing, but now blood.Processor is quite conflated because in this example we know that liver, heart, and lungs are very different components. A better design is:
package blood
type Pumper interface {
// Set current rate, return previous rate.
Rate(cur float64) (prev float64)
// Return current blood pressure.
Pressure() (systolic, diastolic int)
}
type Cleaner interface {
// Remove toxins from blood.
Detox() error
// Return Blood Alochol Content (has user been drinking?).
BAC() float64
}
package air
type Breather interface {
// Breathe in for n seconds. In through nose if true.
Inhale(n float64, nose bool)
// Breathe out for n seconds. Out through nose if true.
Exhale(n float64, nose bool)
// Return current VO2 max rate.
VO2() float64
}
Huge difference! Two of which are important. First, for each component we can better answer the identity test question:
blood.Pumperpumps blood.blood.Cleanercleans blood.air.Breatheroxygenates blood.
Those answers are deceptively simple, yet accurate and complete because the second important difference is: a well-designed component can have a simple responsibility and necessarily complex functionality. This is usually the case. Well-designed components like blood.Pumper, blood.Cleaner, and air.Breather are simple and stable from the high level of design and allow sophisticated functionality. (This is closely related to the open/closed principle.) The reverse (complex responsibility and simple functionality) indicates a poorly-designed component, like blood.Processor, which is likely to become more conflated.
Also note that the well-designed components have domain-specific (not generic computing) names: pump, clean, breathe. This is a good indication of proper design because they make sense in the domain: a human body.
System design looks easy in examples like this, but it is much more difficult in real-world applications. As previously stated, component-based designed (especially with Delineation and Identity) makes it easier to design software and produces better software. So let’s learn more about CBD by looking at refrigerators.
Refrigerators, Cars, & Light Bulbs
Although software systems are intangible, we can learn a lot from physical systems. Refrigerators are a good example because they are simple, reliable, and quite an engineering marvel when you think about it: a self-contained box with only one connection (power cord) keeps one area 0°C and another (the freezer) below freezing. And what does the user have to do? Nothing. Just plug it in. And how long does it “Just Work”? Typically, we expect a good fridge to last at least 10 years.
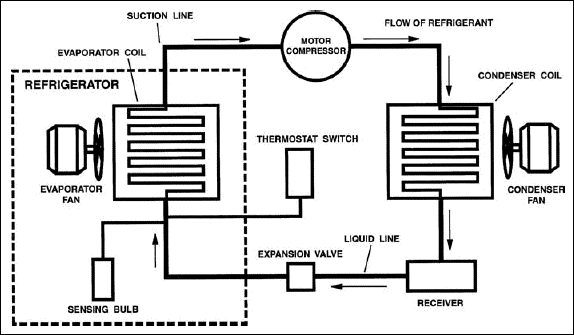
The diagram above is from The 6 Main Components of a Refrigeration System. Please read that blog post.
Refrigerators are more simple than most software systems. A fridge does not have to process thousands of financial transactions per second. But new cars are arguably more complex than most software systems. If cars were only driven slowly on smooth, flat roads in good weather, they would be a lot easier to engineer. But reality is far more challenging, and a car must be able to handle everything: rough roads, pouring rain, snow, desert heat, high altitudes (where air is thin), slow speed (in town) and fast speed (open highway), sudden stops, one driver or heavily loaded, minor collisions, and even major collisions (car: destroyed; occupants: alive). And yet for handling all that, what does the user have to do? Only learn to drive, add fuel, and take it in for occasional maintenance. That is incredible.
At first, cars and refrigerators seem to have little in common. Cars have most refrigerator components, but the real point is: both systems are component-based.
Take a few moments to think about physical and biological systems. Are any not organized around components? Even a simple light bulb has discrete components: base, bulb, and filament. Each of those three can and do vary. I have thought about this for weeks and cannot find a single physical or biological system not organized around components. Granted, some have odd or poorly-conceived components, but nothing is perfect.
Small, well-written components are the foundation of large, well-designed systems. We must think of and see software systems in terms of components. This is challenging because software is intangible. A mechanical engineer can hold the components of a refrigerator, physically put them together and take them apart, and literally see if and how they fit. The expansion valve in hand is the same expansion valve in the refrigerator. It either fits and works, or it doesn’t. Software is different: we write code that compiles with other code we did not write, and the resulting binary runs in an environment which is only partly known to us. The software equivalent of the expansion valve in hand is never the same expansion valve in a running system.
The inherent challenges of software in a running system are why component-based design is the solution: it is easier to reason about and fix small components than a monolithic, entangled system. Thankfully, physical systems are component-based, so when the expansion valve fails, we replace it, not the whole refrigerator. And when the alternator fails, we replace it, not the whole engine. And when the filament burns out… interestingly, we replace the whole light bulb. Perhaps replaceable filament (even LEDs) are a better design?
Component-based software design is easier said than done. Let’s look at an example: the data layer.
The Data Layer
In my experience, the data layer is almost universal in software systems. It can also be called the database layer, the (data) model, data access (objects), or simply data persistence. When designing a system, the question on an engineer’s mind is: “How and where do we persist data?” In a layered architecture, this is usually the bottom layer. In Model-view-controller, this is the model. In Go lang systems, this can be a db package. In Java systems, this can be diffused into classes with an ORM like Hibernate.
Let’s look at a real example: Ruby on Rails directory structure:
app/helpers− The helpers subdirectory holds any helper classes used to assist the model, view, and controller classes. This helps to keep the model, view, and controller code small, focused, and uncluttered.app/models− The models subdirectory holds the classes that model and wrap the data stored in our application’s database. In most frameworks, this part of the application can grow pretty messy, tedious, verbose, and error-prone. Rails makes it dead simple!components− This directory holds components, tiny self-contained applications that bundle model, view, and controller.db− Usually, your Rails application will have model objects that access relational database tables. You can manage the relational database with scripts you create and place in this directory.
For small or highly-focused systems, there is nothing wrong with this framework, i.e. this directory structure and convention for organizing code. But it does not scale for large, complex systems. If you have tried to design or scale a large system within this framework (or any with a distinct data layer), you have probably already encountered two problems. First: cross cutting. Please read that blog post. I agree with the author’s solution:
The cross cutting codes are injected to the other layers by different ways of injecting (constructor , getter or setter, method ) or using by dependency injection.
However, one cross-cutters leads to many, resulting in layers that look more # than =. Another common problem: the “architecture sinkhole anti-pattern”, which you can read about in Software Architecture Patterns (page 7).
Every technical solution has its problems (yes, even component-based design), so I would not dismiss the data layer and frameworks like this for purely technical reasons. However, the technical problems allude to a deeper, philosophical problem: organization by kind. Controllers, models, helpers, views, and (confusingly) components which bundle those together—these are lumped together by kind. Think of physical systems again. Are any organized by kind? Are the wheels of a car in the same place? Are the windows of a building in the same place? Are the bones in your body in the same place? Organization by kind in an ontological exercise. It is not software design.
Organization by kind is the antithesis of component-based design. When engineers struggle to design (or refactor) a system, the problem is often being stuck in an implicit or explicit system of organization by kind, like data layers or MVC, respectively. The solution is to rethink the system in terms of components not kinds.
From Layer to Component
We must think of and see software systems in terms of components. Forget the data layer. Data is not a layer; the whole system is data. Everything is data. Data is everywhere.
To illustrate, let’s use the joblog component of Spin Cycle, a large open-source project my colleagues and I are developing. The fact that we can study the joblog in isolation is a direct result and benefit of component-based design. Spin Cycle has many components, but we can ignore them. We only need to know that the joblog stores job log entries (JLE). (That’s another good example of the identity test question.) It is sufficient background to say that Spin Cycle runs requests: infrastructure tasks, like “allocate host”, which are accomplished by a series of discrete jobs. Each job is logged by the joblog:
package joblog
type Store interface {
Create(requestId string, jle proto.JobLog) (proto.JobLog, error)
Get(requestId string, jobId string) (proto.JobLog, error)
GetFull(requestId string) ([]proto.JobLog, error)
}
func NewStore(db *sql.DB) Store
The code above is the whole joblog component. It is tiny, but it illustrates many points. First and to the main point: no data layer or model. To appreciate this, consider instead how it would be organized in the Ruby on Rails framework:
- app/helpers/joblog.rb
- app/models/joblog.rb
- components/joblog.rb (?)
- db/joblog (?)
models/joblob.rb seems straightforward, and I suppose the logic of fetching JLE fits in helpers/joblog.rb. Or should everything be in component/joblog.rb? I’m not sure about db/, but it seems relevant because we will need a database to persist the JLE. — But wait, do you see what is happening? We are having an ontological debate: model vs. helper vs. component. This is the wrong debate because it forces us to organize by kind and design the system for the framework rather than delineating the system into necessary and sufficient components with single responsibilities.
Design components to fit the system. Do not design the system to fit a framework.
But what about…
Architectural patterns? These are important, but they usually apply at a higher level of design. For example, the microservices architectural pattern does not help design a specific system, it is a pattern related to systems and interactions of systems. While a specific system might be a microservice, that architecture is higher-level than the components that make up the microservice. The same is true for other architectural patterns, like the event-driven pattern. However, other architectural patterns do apply to, or at least influence, system design. For example, the layered architecture indirectly designs a system by organizing common functionality (presentation, business logic, data access, etc.) into layers. And the microkernel architecture pattern requires a microkernel in the system design, so it is much lower-level than the microservices pattern. This blog post is about the internal design and organization of a system, so architectural patterns, while important, are out of scope.
Software design patterns? These are important, but they usually apply at a lower level of design. However, like architectural patterns, there are some software patterns, like the repository pattern, that apply to system design. The joblog.Store example above is a repository. But generally speaking, when designing system components, software patterns are implementation details of components.
Classes and OO? Classes, packages, objects, interfaces—all these apply at a lower level of design. However, these and system design go hand-in-hand because the former implement the latter. A rough hierarchy from high-level to low-level: architectural patterns > components > software patterns > classes/objects/interfaces > functions/methods > lines of code. This blog post focuses on components, but a book-length treatment of system design would address every level. Therefore, component-based design does not negate or replace class design, it’s simply another topic.
ORMs? Depends on how they are used. Often, they are used to provide an implicit, semi-transparent data layer by automatically storing and retrieving objects. Problem is, this tends not to scale, resulting in code to adapt the system to the ORM and vice versa. If the adapter code is contained within and hidden behind the interface of a component, that’s ok; but if it begins to cross component boundaries, then the system design is being made to fit the ORM, which is not good.
Cross-cutting concerns? Logging and auth are two common cross-cutting concerns. Component-based design plus dependency inversion plus a (pseudo or real) singleton provide a clean solution. And if the cross-cutter needs to vary, e.g. context-based structured logging, add dependency injection, too. That sounds fancy, but really it just means: pass a single instantiation of the component responsible for the cross-cutting functionality to other components. Notice how component-based designs and SOLID principles align with respect to abstractions: components require abstractions to form their delineations, and SOLID principles require abstractions to be implemented properly.
Conclusion
The idea for this blog post arose when a colleague asked for suggestions about organizing a system written in Go. Component-based design is the solution for software systems as well as the ubiquitous design of physical systems. Physical systems have certain limitations which preclude poor design. For example, the tires of a car cannot be grouped together, else the car will not work. Software, however, lacks such limitations, allowing engineers to do almost anything. But the more choices we have, the more difficult it is to know which choice is best.
CBD provides constructive limitations: it requires us to break down the system into components, then build it back up from parts (components) to whole (system). Without limitations, engineers can and often do jump right to implementing the whole. After all, engineers are hired to write code, so write code! But we know the usual result: an unorganized, highly-entangled mess. Eschewing limitations is easier, but to create well-designed software—the rare kind of software that’s a delight to work with and stands the test of time—think component-based design.
Copyright 2025 Daniel Nichter