
COMMIT Latency: Aurora vs. RDS MySQL 8.0
 Feb 18, 2023
Feb 18, 2023Let’s examine COMMIT latency on Aurora v2 (MySQL 5.7) vs. Aurora v3 (MySQL 8.0) vs. RDS MySQL 8.0 2-AZ vs. RDS MySQL 8.0 3-AZ “cluster”.
Why COMMIT Latency?
COMMIT is when MySQL incurs storage latency to make data changes durable.
Before that, reads and writes are ideally (but not always) in-memory operations.
Therefore, CPU and memory (and a few other concerns) affect query response time before COMMIT, but on COMMIT response time is largely a result of how fast the storage system can physically write and flush.
In the cloud, storage is usually network-backed, so COMMIT latency can be orders of magnitude higher than locally-attached SSDs—milliseconds versus microseconds.
I use the term latency specifically because storage has true latency: delay inherent in a system. Readers of my book know that normally I use (and insist upon) the term response time, not latency, because response time is not a delay inherit in a system. But COMMIT latency is true latency.
COMMIT latency is also important because it affects transaction throughput (transactions/second [TPS]).
Presuming negligible lock waits and intra-query delays (caused by the application), TPS is limited by how fast MySQL can finish the transaction on COMMIT.
For example, in the cloud a transaction might have these response times:
BEGIN -- 0 ms
SELECT ... -- 5 ms
UPDATE ... -- 1 ms
COMMIT -- 20 ms (latency)
The SELECT and UPDATE take almost no time, but the COMMIT takes a full 20 milliseconds because it’s writing and flushing to an EBS volume, for example.
Given that latency, the transaction is limited to about 50 TPS (1,000 ms / 20 ms = 50) per thread.
If, for example, you have 48 threads (clients), you’ll get about 50 * 48 = 2,400 TPS.
Point being: if your application uses multi-statement transactions, COMMIT and TPS can be more important than individual query response time when the queries are fast but the storage is slow.
Benchmarks
TL;DR: Aurora has the lowest (fastest) and most stable COMMIT latency.
Click charts for full-size PNG image.
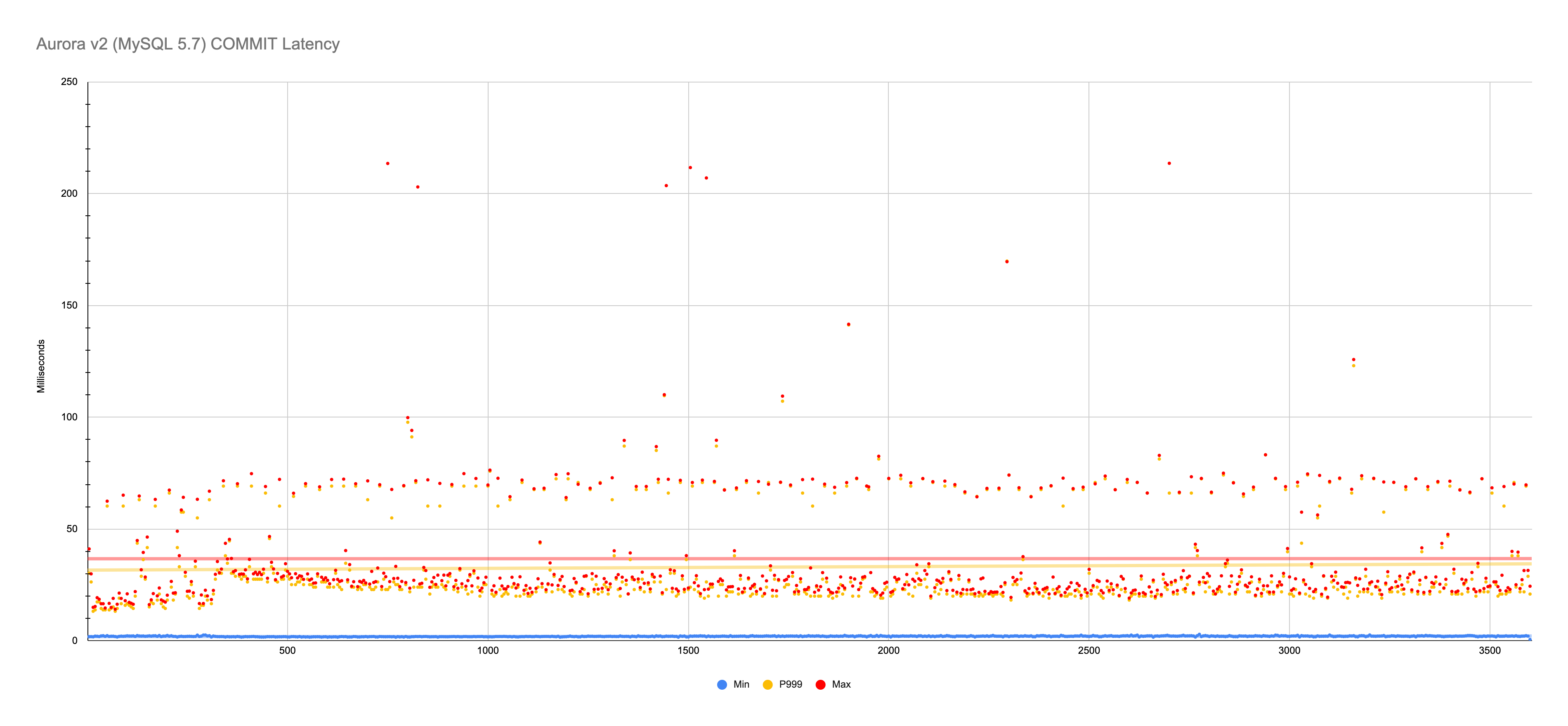
Min 574 μs or 1.56 ms → Max 214 ms
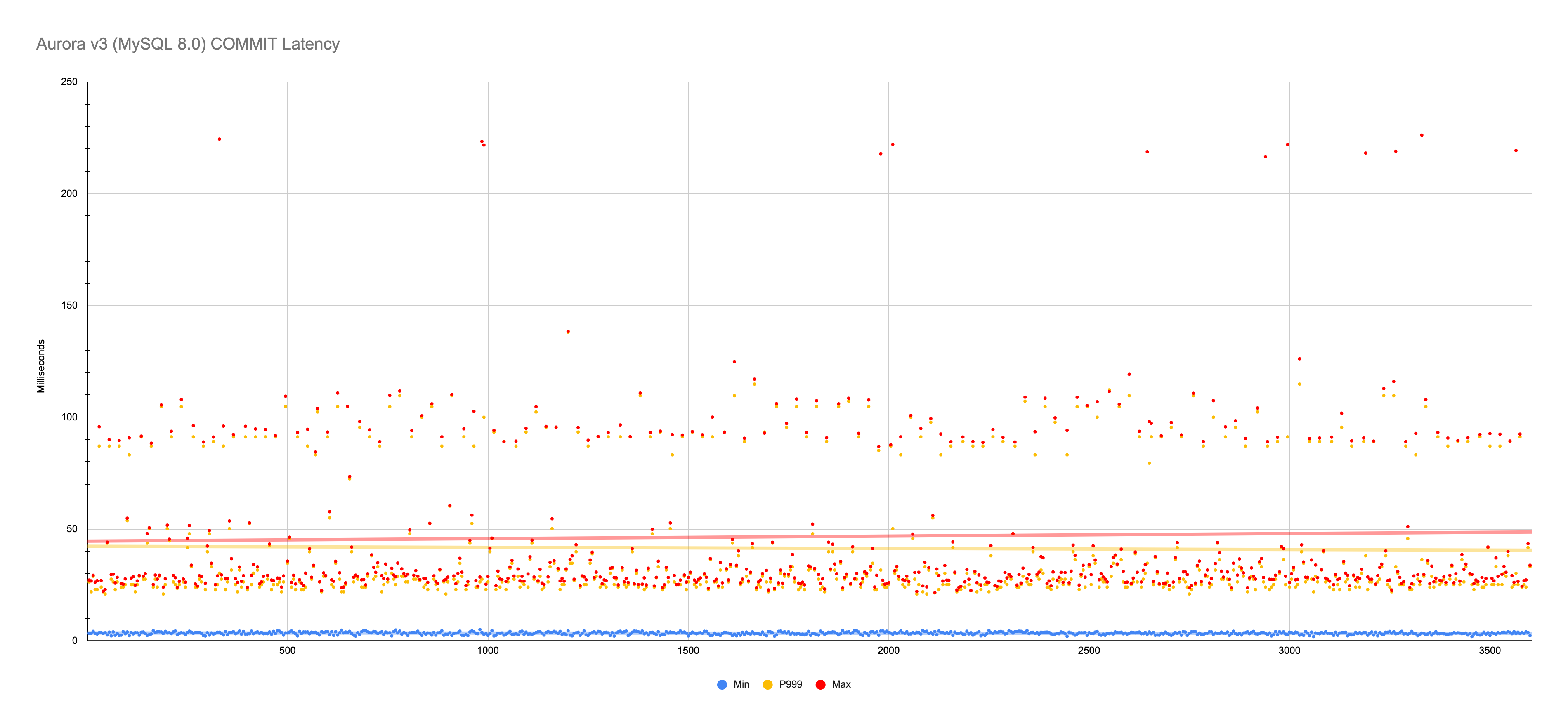
Min 1.86 ms → Max 226 ms
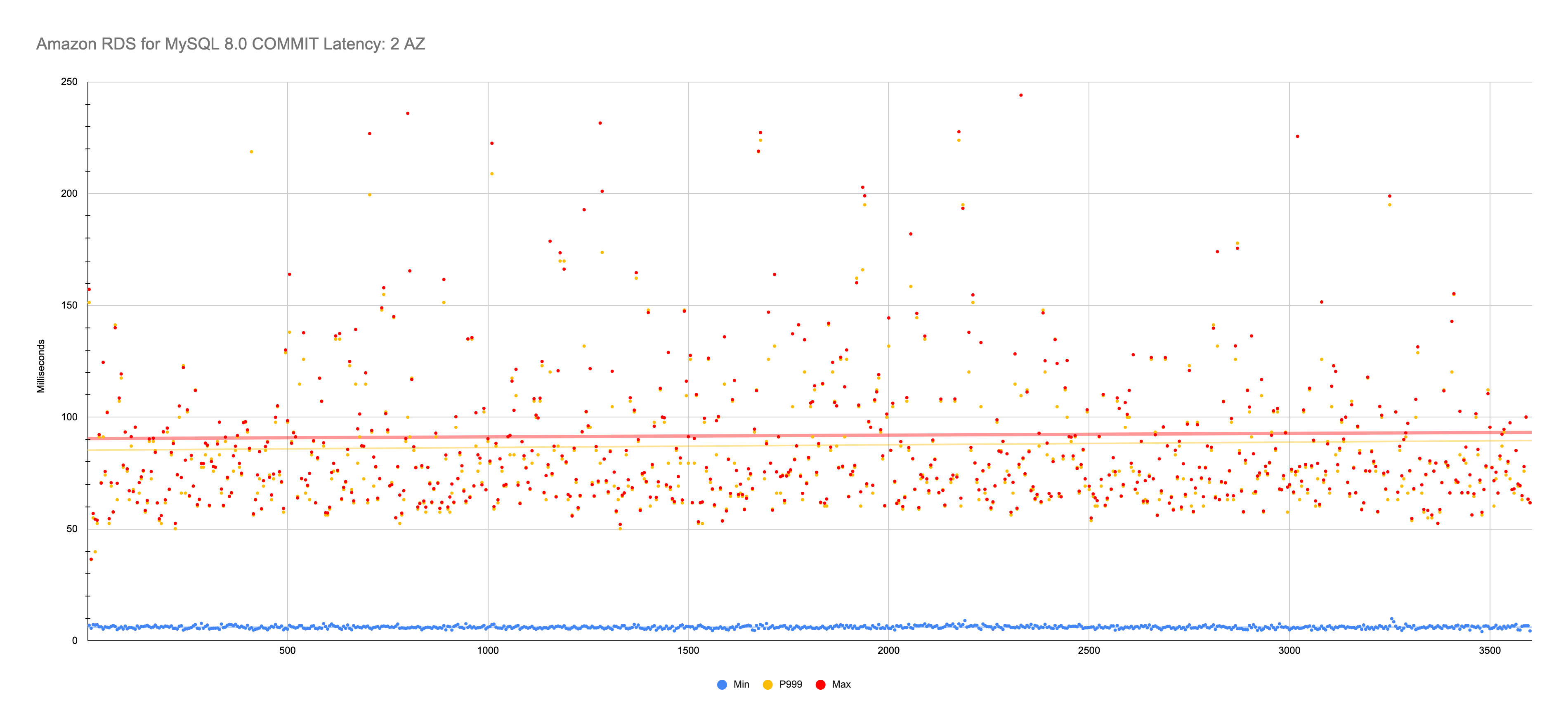
Min: 4.08 ms → Max: 922 ms; 780 ms; 382 ms
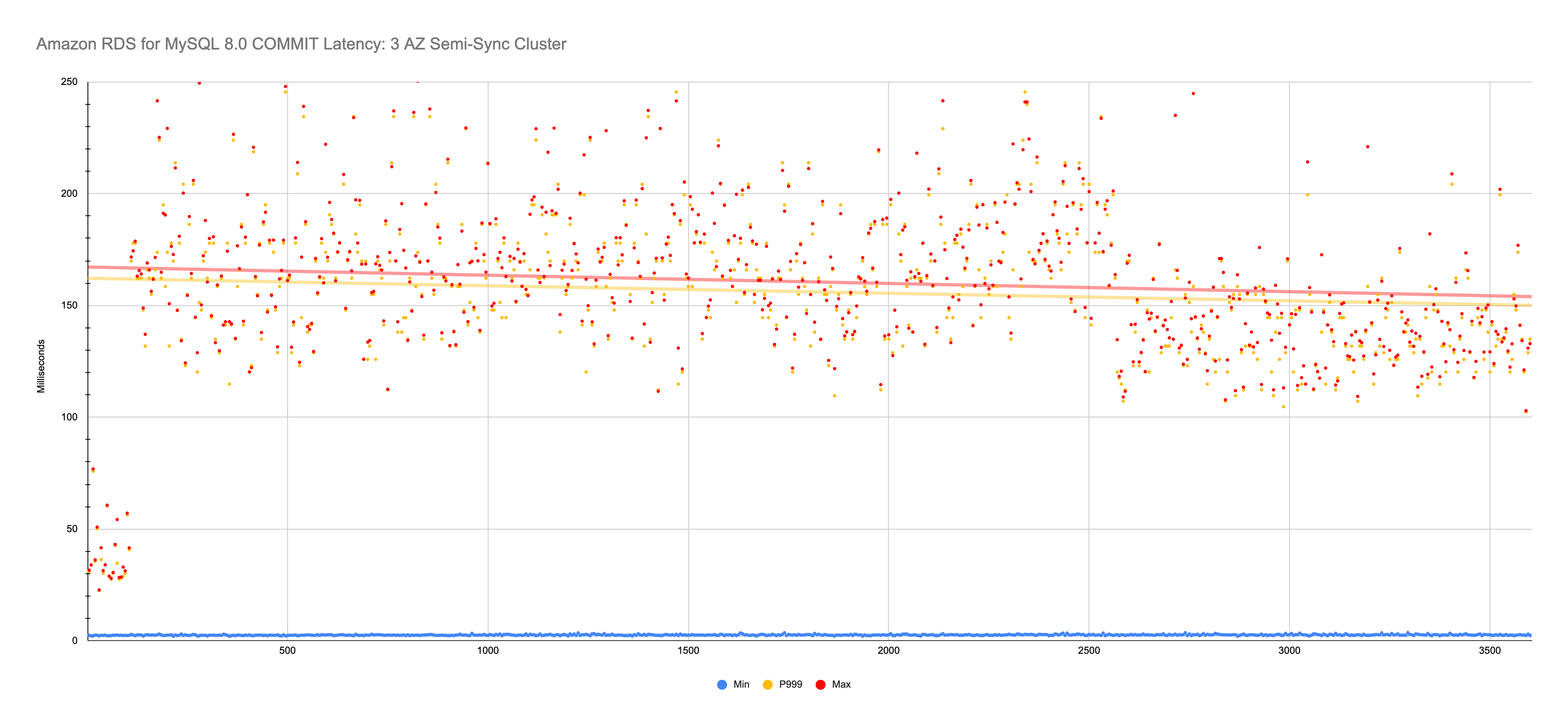
Min 1.93 ms → Max 345 ms
Click charts for full-size PNG image.
Observations
This post is intended for MySQL experts, so I’ll let the four charts above speak for themselves. However, I’ll make a few points:
It’s no surprise that Aurora beats standard RDS for MySQL: the former was purpose-built for more efficient storage I/O. You can find lots of resources published by Amazon about Aurora storage, so I won’t repeat them here.
Aurora v2 and v3 have similar
COMMITlatency, but the v3 values are slightly higher and more variable. For the minimum, v2 is very steady but v3 shows more variation, but the different is microseconds; both have a minimum of roughly 2 ms. For the P99.9 and maximum, v2 values are tightly clustered in the 20-30 ms range with semi-regular spikes in the 60-70 ms range, but v3 is loosely clustered in the 20-30 ms range with semi-regular spikes around 100 ms. I don’t know if Aurora v2 and v3 have different storage servers (only Amazon would know), so the slight difference in numbers might be random performance differences inherit to multi-tenant (shared) hardware.The 574 microsecond (μs)
COMMITlatency observed on Aurora v2 is such a surprising outlier that I would dismiss it, especially since it’s the only sub-millisecond measurement observed in tens of millions ofCOMMIT. It might even be an error of some sort.RDS for MySQL 8.0 (2 AZ) has double the minimum
COMMITlatency as Aurora: about 4 ms. I suspect this is due to redo log flushing (and full page writes) and synchronous EBS writes to the second AZ—neither of which Aurora have because its storage is completely different. 4 ms isn’t terrible; it’s the P99.9 and max that are troublesome…RDS for MySQL 8.0 (2 AZ) has P99.9 and max
COMMITlatency in the 50-100 ms range with random spikes all the way up to 922 ms. The max value of 922 ms occurred only once. The 2nd highest was 780 ms that also occurred only once. The 3rd highest value was 382 ms, which was more representative of reoccurring maxCOMMITlatency. No matter how you look at it, these values are troublesome. Not knowing if aCOMMITwill take 50 ms or double (100 ms) or maybe an unacceptable half-second (or more!) makes working with the database onerous for developers who need reliable write transaction throughput.RDS for MySQL 8.0 (3 AZ) “cluster” is an interesting product. Amazon calls it “multi-AZ clusters”, but I think that’s confusing for a couple reasons, so I call it 3-AZ “clusters”. If you’re not familiar with this product (whatever you call it), read the link. On the one hand, the locally-attached NVMe seem to help keep minimum
COMMITlatency consistency low: about 2 ms, same as Aurora. But the variability up to the P99.9 and max is terrible: widely scattered around 150 ms. So theCOMMITmight take 2 ms, or 75 times longer, or somewhere in between. Crazy. My guess is that this is due to semi-sync replication, but more benchmarking of this product is needed to know for sure.
Methodology
You’re not going to recognize this methodology or benchmark run in general because I developed a new benchmark tool last year (2022) that I’ll release later this year. But for now, I’ll dump some information how I obtained the values for the charts above so it’s not all smoke and mirrors.
Database
- Configuration
- Amazon default parameter group plus binary logging with GTID
- Exception: query cache disabled in Aurora v2 (AWS enables it by default)
- Replication
- Async replication with binary logs and GTID from AWS us-east-1 to us-west-2
- Exception: 3 AZ “cluster” uses semi-sync replication with GTID in us-east-1 only
- Instance class
- db.r5.12xlarge (24 CPU; 48 vCPU; 384 GB RAM)
- Active/primary/writer in AWS us-east-1
- Clients
- 48 total
- 16 us-east-1a
- 16 us-east-1b
- 16 us-east-1c
Schema
CREATE TABLE customers (
id bigint NOT NULL AUTO_INCREMENT,
c_token varbinary(255) NOT NULL,
country char(3) NOT NULL,
c1 varchar(20) DEFAULT NULL,
c2 varchar(50) DEFAULT NULL,
c3 varchar(255) DEFAULT NULL,
b1 tinyint NOT NULL,
created_at timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (id),
UNIQUE KEY (c_token),
KEY (country)
) ENGINE=InnoDB
CREATE TABLE balances (
id bigint NOT NULL AUTO_INCREMENT,
b_token varbinary(255) NOT NULL,
c_token varbinary(255) NOT NULL,
version int NOT NULL DEFAULT '0',
cents bigint NOT NULL,
currency varbinary(3) NOT NULL,
c1 varchar(50) NOT NULL,
c2 varchar(120) DEFAULT NULL,
b1 tinyint NOT NULL,
created_at timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (id),
UNIQUE KEY (b_token),
KEY (c_token)
) ENGINE=InnoDB
CREATE TABLE xfers (
id bigint NOT NULL AUTO_INCREMENT,
x_token varchar(255) NOT NULL,
cents bigint NOT NULL,
currency varbinary(3) NOT NULL,
s_token varchar(255) NOT NULL,
r_token varchar(255) NOT NULL,
version int unsigned NOT NULL DEFAULT '0',
c1 varchar(50) DEFAULT NULL,
c2 varchar(255) DEFAULT NULL,
c3 varchar(30) DEFAULT NULL,
t1 timestamp NULL DEFAULT NULL,
t2 timestamp NULL DEFAULT NULL,
t3 timestamp NULL DEFAULT NULL,
b1 tinyint NOT NULL,
b2 tinyint NOT NULL,
created_at timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (id),
UNIQUE KEY (x_token),
KEY (s_token, t1),
KEY (r_token, t1),
KEY (created_at)
) ENGINE=InnoDB
Transaction
This is not—I repeat: not—how money is transferred in real-world systems. This is a fake transaction designed to stress MySQL in various ways.
BEGIN
-- Select random customer and one of their balances (from cust/bal)
SELECT c_token, country FROM customers WHERE id=@id
SELECT b_token FROM balances WHERE c_token=@from_cust LIMIT 1
-- Select another random customer and their balance in the same country (to cust/bal)
SELECT c_token FROM customers WHERE id BETWEEN @id_1000 AND @PREV AND country=@country LIMIT 1
SELECT b_token FROM balances WHERE c_token=@to_cust LIMIT 1
-- Start new transfer between customers
INSERT INTO xfers VALUES (NULL, @x_token, 100, 'USD', @from_bal, @to_bal, 1, @c1, @c2, @c3, NOW(), NULL, NULL, 1, 0, NOW(), NOW()) -- 6
-- Lock then debit from customer balance
SELECT id, version FROM balances WHERE b_token=@from_bal FOR UPDATE
UPDATE balances SET cents=cents-100, version=version+1 WHERE id=@from_id
-- Lock then credit to customer balance
SELECT id, version FROM balances WHERE b_token=@to_bal FOR UPDATE
UPDATE balances SET cents=cents+100, version=version+1 WHERE id=@to_id
-- Finish transfer
UPDATE xfers SET t2=NOW(), c3='DONE' WHERE id=@xfer_id
COMMIT
Data Sizes
| customers | balances | xfers | |
|---|---|---|---|
| Rows | 500,000,000 | 1.5 billion (3x per cust.) | ~2 billion |
| Data Size | 200 GB | 700 GB | 1.0 TB |
Data Access
Uniform random 100M customers between IDs 250,000,000 and 500,000,000.
Thank You
In this blog post I focus on only COMMIT latency on four Amazon products, but I did over 20 benchmarks recently on all Amazon products for MySQL.
Benchmarks like these are not cheap.
Thank you to my employer for making this work possible:
Copyright 2025 Daniel Nichter