
Are Aurora Performance Claims True?
Amazon claims that Aurora has “Up to 5X the throughput of MySQL”. Is it true? It wasn’t easy to find the truth, but I kept digging until I found it. This is a long read; let’s chase the rabbit all the way down the hole.
Part b'01'
A Database Is Not a Truck
When Ford says the new F-150 is more fuel efficient, it’s logical to believe the claim because it’s relatively simple and measurable. It’s also federally regulated and tested. And although there is some fine print about driving conditions, ambient temperature, etc., the claim is going to prove true for you (unless your driving habits are really bizarre). There’s an expression for this: Your mileage may vary.
Whereas your truck is the same as what Ford “benchmarks”, your database is not the same as what AWS benchmarks. Consequently, with database benchmarks your mileage won’t simply vary, it won’t make any sense. And the differences can be huge.
The results of any database benchmark are true only for the conditions of the benchmark:
- MySQL version
- MySQL configuration
- Hardware specs
- CPUs
- Storage
- RAM
- Network
- OS/kernel and configuration
- Benchmark workload:
- Schemas
- Data
- Queries
- Access patterns
- Unrelated workloads
- Runtime
When AWS claims “Up to 5X the throughput of MySQL”, that’s true only for the conditions of the benchmark. When the conditions aren’t true the claim is not false, it’s simply meaningless—like telling someone they can get a million dollars but not telling them how.
Moreover, certain conditions are complex on their own, which makes them difficult to match. Like MySQL configuration: people have been “fine tuning” it for more than 20 years. And queries: many books have been written about query optimization.
If you're a software engineer, read Efficient MySQL Performance. It's one of the best books on MySQL performance ever published.
To make matters more complex, database performance is more sensitive to some conditions than others. For example, it’s common knowledge that database performance is sensitive to RAM: more RAM, better performance. But even these caveats have caveats: more RAM doesn’t always yield better performance; there are cases when it doesn’t matter.
Whenever you hear or read about a database benchmark, your first thought and question should be: “Under which conditions?” If the conditions are similar to your database and application, then the results might be applicable to you. If not, then don’t get excited: like a deranged AI chat bot, benchmarks can be made to say anything. Be skeptical.
Marketing the Mind
Good marketing is quick and impactful. How, then, can meticulous benchmarks be used for marketing? Craft a benchmark that yields an impressive number, market that, and bury the details. Since humans are rife with logical fallacies, they will believe the impressive number.
But surely engineers aren’t that naïve or gullible to believe marketing claims at face value? Yes and no. Good marketing doesn’t have to make us believe every detail (it rarely provides details); it merely needs to make us receptive to an idea. As fallible humans, our brains will fill in the details, and we’ll convince ourselves to believe whatever we want. This is why car commercials often focus on beautiful, happy people: they have nothing to do with the car, but the marketing isn’t selling a car, it’s selling the idea that car = beautiful and happy, and these two are universal best sellers.
If AWS says Aurora is up to 5X faster than MySQL, then it doesn’t matter if you believe the “5X” part. We know that AWS doesn’t lie (somehow the claim is true, else they’re in legal trouble), and now we’re receptive to the idea that Aurora is faster than MySQL. And what’s more: now there’s an open question—a mystery—and humans love to solve those: is it true that Aurora has up to 5X the throughput of MySQL?
As a long-time MySQL DBA, I must solve this mystery.
Origin Story
AWS isn’t shy about the Aurora performance claim:

(Source https://aws.amazon.com/rds/aurora/features/)
But where are the details? The conditions? You have to keep digging.
The FAQ explains the 5X claim in a little more detail:

(Source: https://aws.amazon.com/rds/aurora/faqs/)
100,000 UPDATEs/sec, five times higher than MySQL running the same benchmark on the same hardware
That, specifically, is the claim that I intend to verify: write throughput. Even though 500k SELECT/s is impressive, I don’t care about read throughput because reads are easy to scale compared to writes.
The link at the bottom of that FAQ paragraph leads to a PDF titled Amazon Aurora Performance Assessment: Technical Guide (June 2019).
But let me save you a lot of wasted time and effort: that technical guide is wrong.
It wouldn’t be a good mystery if there weren’t twists and turns. So while it’s a bit annoying for a technical guide to be wrong, I am appreciative for the opportunity to solve and write about an old mystery.
Part b'10'
Dead Herrings & Red Ends
Figure 1 on page 2 (PDF page 6) of the technical guide is shown below: a single c5.18xlarge EC2 instances and an r4.16xlarge Amazon Aurora instance.
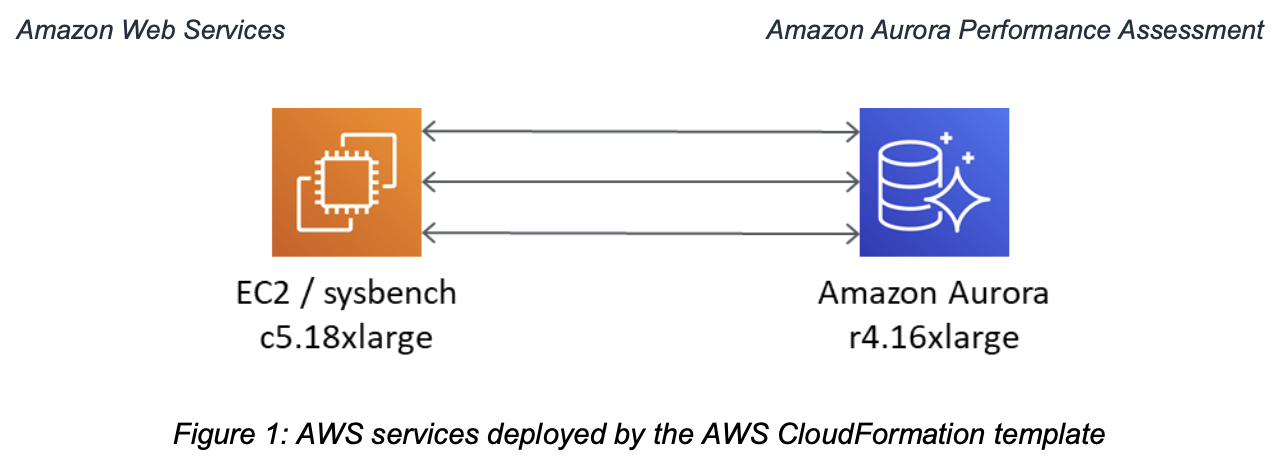
There are two issues here:
- The FAQ (see above) says “SysBench on r3.8xlarge instances” (emphasis mine)
- The FAQ does not say the size of the Aurora instance
Changing from an unspecified number of r3.8xlarge instances to a single c5.18xlarge is a nontrivial change of conditions. Not knowing the original Aurora instance size and presuming an r4.16xlarge is also a nontrivial change of conditions.
If we give AWS the benefit of the doubt and simply run the CloudFormation template in the technical guide, we run into another issue: it doesn’t work. At the time of this writing, AWS provides the template at https://s3.amazonaws.com/aurorabenchmark/labstack.yml, but the links change over time.
Let me save you more wasted time and effort by showing you the problem:
EngineVersion: !If [Is57, 5.7.mysql_aurora.2.04.1, 5.6.mysql_aurora.1.19.0 ]
Although this template is supposed to fully automate the benchmark, it’s amusing (or frustrating) that you still need to know a bit about Aurora to make it work even when the problem is pointed out.
The template runs either Aurora v1 or v2: the former based on MySQL 5.6, and the latter based on MySQL 5.7.
Aurora v1 recently reached its EOL, and I suspect provisioning a new 5.6.mysql_aurora.1.19.0 hasn’t worked for awhile.
Likewise, you can’t provision a new 5.7.mysql_aurora.2.04.1 either.
AWS is generous with support for old versions, but it does occasionally remove old versions (usually for security reasons).
No problem, just change the Aurora v2 version wherever it appears (multiple lines), like:
EngineVersion: !If [Is57, 5.7.mysql_aurora.2.11.1, 5.6.mysql_aurora.1.19.0 ]
Then the template will work, for awhile at least.
Although we’re ignoring Aurora v1 because it’s EOL, it’s important to point out that this is a huge change of conditions: the original Aurora benchmark, on which the 5X performance claim depends to this day, was run on a different version of Aurora. Changing the database version would disqualify most benchmark results, but let’s continue because mysteries remain, and we haven’t even begun to dig into the pertinent details yet.
Sysbungled
You fix the AWS-provided CloudFormation template, create all the resources (don’t peek behind the curtain yet), then run the sysbench write workload and wait…
Lucky for you, in the AWS-provided script I changed --time=86400 (1 day) to --time=3600 (1 hour).
Although runtime is one condition of a database benchmark, in this case I know that this change doesn’t affect the results.
One hour later, you check the CloudWatch charts created by the template:
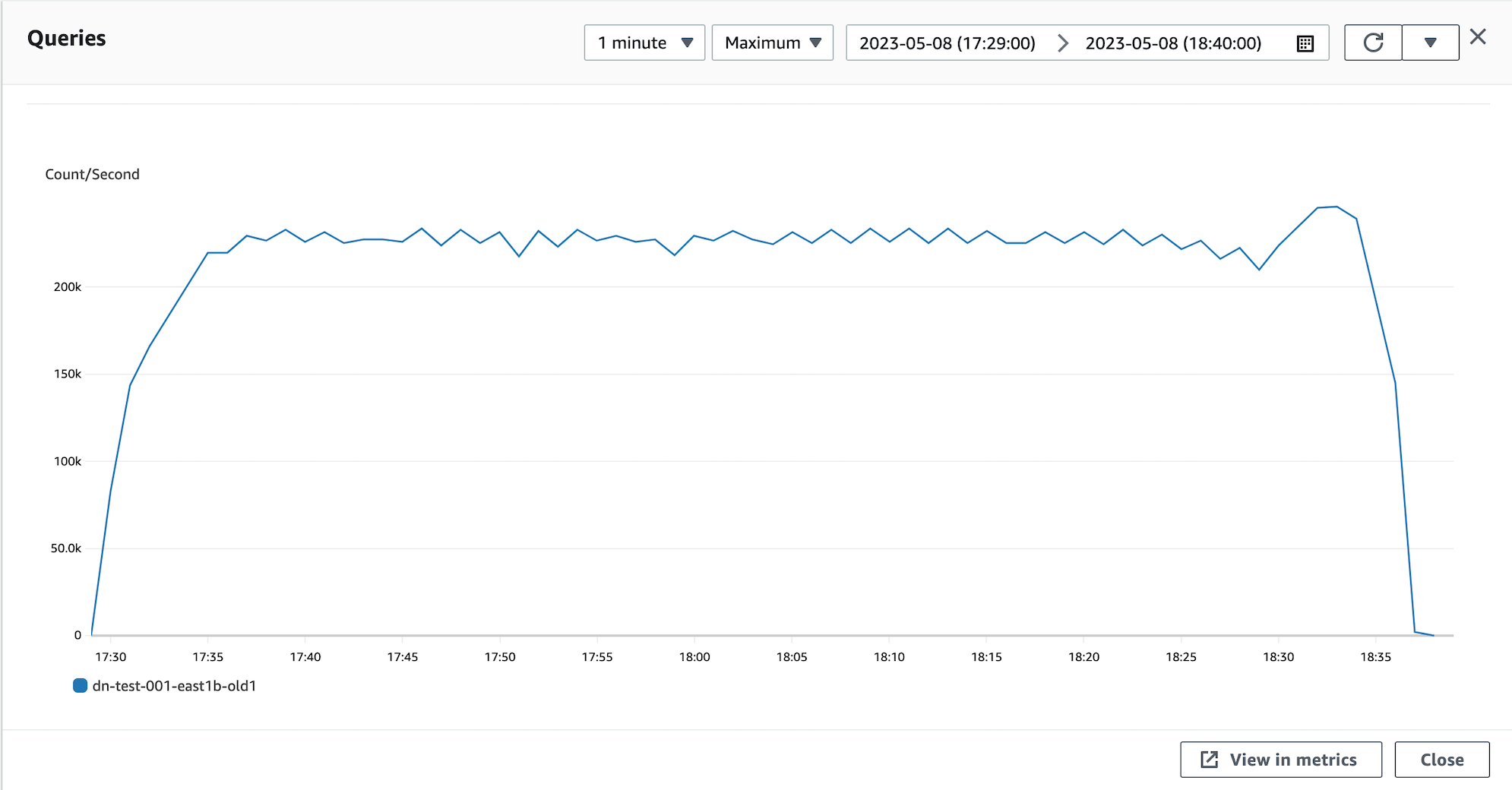
Chart 1: Aurora v2 QPS on 2019 benchmark
More than 200,000 QPS!? Wow! Success, right?
Hold on there, cowboys and cowgirls. Scroll back up to the Amazon FAQ: it says 100,000 UPDATEs/sec. So let’s check that chart:
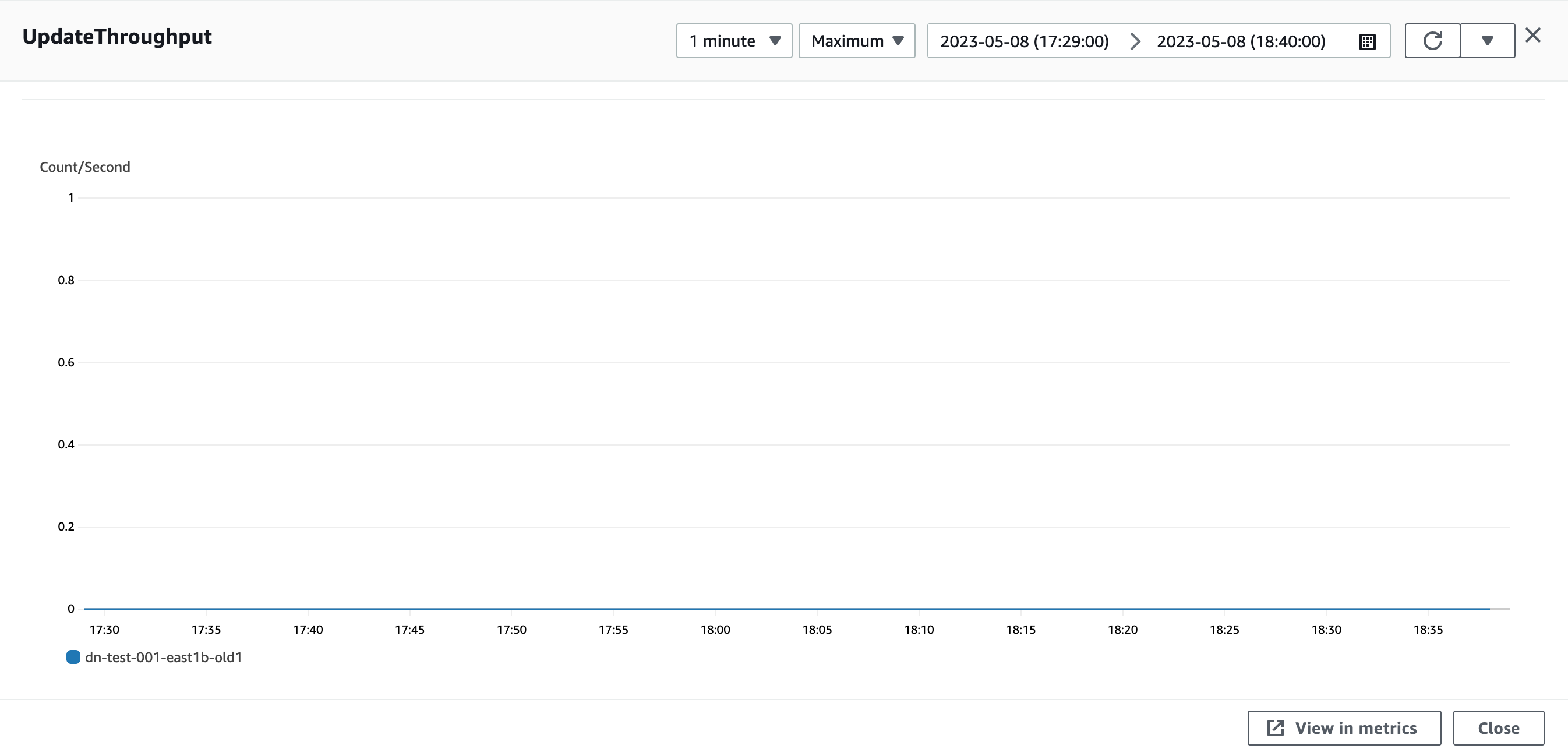
Chart 2: Aurora v2 UPDATE throughput on 2019 benchmark
That’s what nobody calls “pancake performance”, and it’s no joke: not one, single UPDATE.
MySQL [sbtest]> SHOW GLOBAL STATUS LIKE 'Com_update';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Com_update | 0 |
+---------------+-------+
But the INSERT throughput chart looks suspicious:
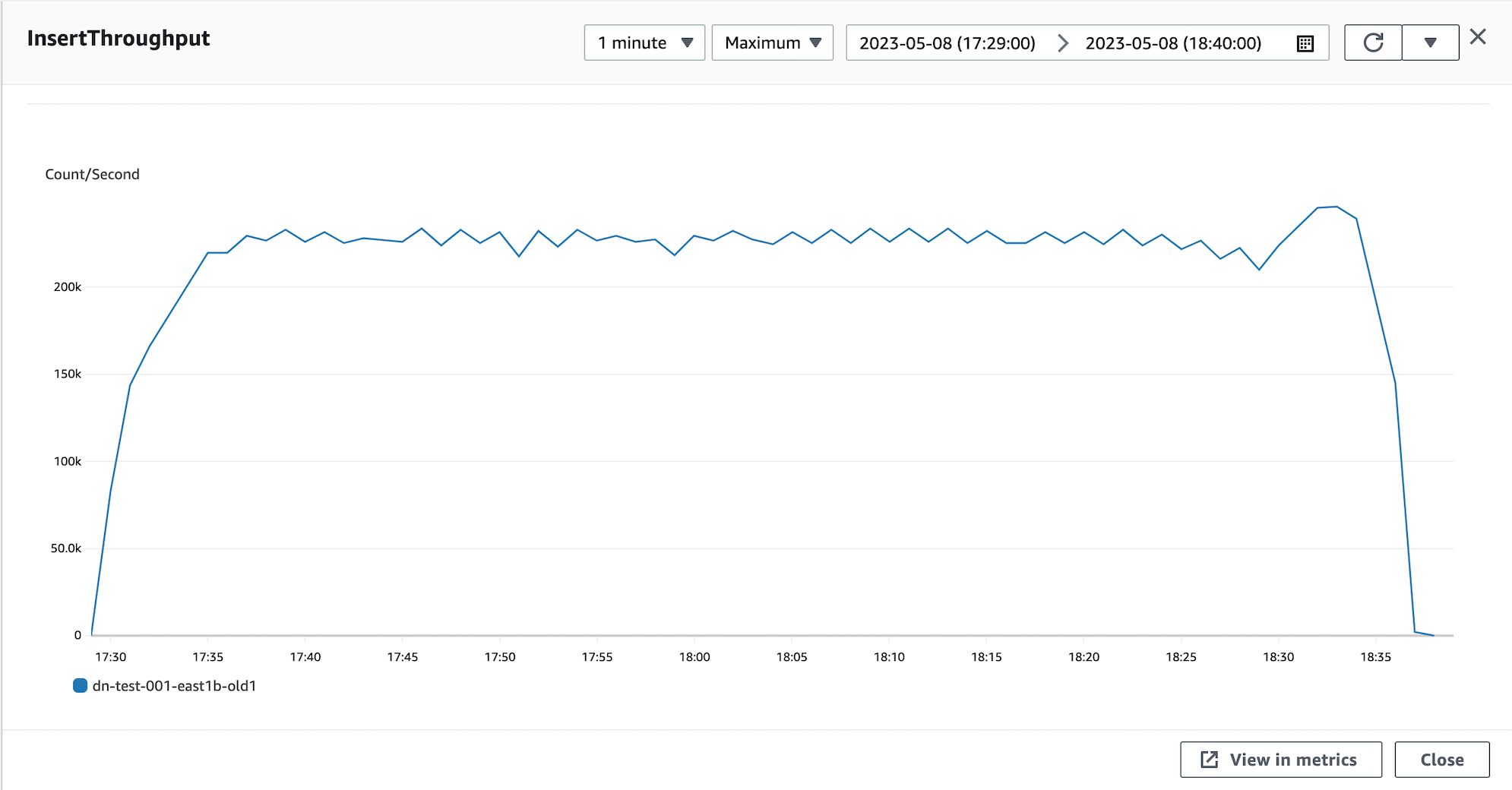
Chart 3: Aurora v2 INSERT throughput on 2019 benchmark
Yes, that chart is identical to the QPS chart: the benchmark is supposed to be a write workload, but instead it’s an INSERT-only workload. The command from the CloudFormation template to run the write workload proves it (in the yellow circle):
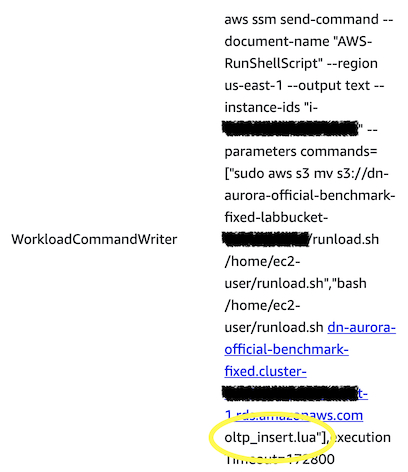
oltp_insert.lua is an INSERT-only workload:
1sysbench.cmdline.commands.prepare = {
2 function ()
3 if (not sysbench.opt.auto_inc) then
4 -- Create empty tables on prepare when --auto-inc is off, since IDs
5 -- generated on prepare may collide later with values generated by
6 -- sysbench.rand.unique()
7 sysbench.opt.table_size=0
8 end
9
10 cmd_prepare()
11 end,
12 sysbench.cmdline.PARALLEL_COMMAND
13}
14
15function prepare_statements()
16 -- We do not use prepared statements here, but oltp_common.sh expects this
17 -- function to be defined
18end
19
20function event()
21 local table_name = "sbtest" .. sysbench.rand.uniform(1, sysbench.opt.tables)
22 local k_val = sysbench.rand.default(1, sysbench.opt.table_size)
23 local c_val = get_c_value()
24 local pad_val = get_pad_value()
25
26 if (drv:name() == "pgsql" and sysbench.opt.auto_inc) then
27 con:query(string.format("INSERT INTO %s (k, c, pad) VALUES " ..
28 "(%d, '%s', '%s')",
29 table_name, k_val, c_val, pad_val))
30 else
31 if (sysbench.opt.auto_inc) then
32 i = 0
33 else
34 -- Convert a uint32_t value to SQL INT
35 i = sysbench.rand.unique() - 2147483648
36 end
37
38 con:query(string.format("INSERT INTO %s (id, k, c, pad) VALUES " ..
39 "(%d, %d, '%s', '%s')",
40 table_name, i, k_val, c_val, pad_val))
41 end
42end
INSERT is a write, but for reasons I’ll clarify later, I’m certain that running this workload is mistake.
This makes me suspicious of the AWS-provided script to run sysbench. So let’s examine the relevant code that prepares and runs the write workload:
1 # Prepare for write-only test
2 /home/ec2-user/sysbench/src/sysbench ./$2 --tables=250 --table-size=25000 --threads=250 \
3 --auto-inc=off prepare
4
5 # Launch 250 sysbench clients (16,000 connections)
6 for i in {1..800}
7 do
8 # Execute read-only test
9 (/home/ec2-user/sysbench/src/sysbench ./$2 --tables=250 --table-size=25000 --threads=20 \
10 --time=86400 --range_selects=off --db-ps-mode=disable --skip_trx=off --auto-inc=off \
11 --mysql-ignore-errors=all run)&
12
13 # Sleep one second
14 sleep 1
15 done
If you look closely at that script, you’ll find more discrepancies and questions, but we still have a long road ahead of us, so I will point out only one: --auto-inc=off.
The default is auto-inc on.
Turning it off changes a condition of the benchmark: it avoids the auto-inc lock, and locks affect performance.
But that’s not even the weird part: look up at oltp_insert.lua lines 1–7: --auto-inc=off causes sysbench not to insert rows on prepare, which means all the tables are empty despite --table-size=25000.
This is another significant change of condition because, if you read my book, you know that data is dead weight to MySQL (like a boulder it has to push uphill).
With zero data, query response time can be virtually zero—maximum performance!
oltp_insert.lua line 35 might be a bug. With --table-size=25000, my understanding is that there are supposed to be 25,000 rows, but this is not the case:MySQL [sbtest]> select count(*) from sbtest1; +----------+ | count(*) | +----------+ | 1112785 | +----------+And that line generates positive and negative values between, roughly, [-2^32, 2^32]:
MySQL [sbtest]> select min(id), max(id) from sbtest1; +-------------+------------+ | min(id) | max(id) | +-------------+------------+ | -2147466742 | 2147478066 | +-------------+------------+Very different conditions: 25k rows/25k cardinality vs. 1.1M rows/1.0M cardinality.
All these errors and inconsistency make me certain that the current Aurora benchmark, as written in the 2019 technical guide and implemented in the accompanying code, is wrong. But I’m also certain this is a simple mistake and oversight by AWS, not an intentional attempt to game the numbers in their favor. AWS documents are usually precise and reliable, so this an exception in my experience.
We’re a little more than half way there. Before moving on, let’s peek behind the curtain of the AWS-provided CloudFormation template.
Behind the Curtain
The AWS CloudFormation template creates a new cluster parameter group, which reconfigures MySQL:
innodb_flush_log_at_trx_commit: 0
innodb_sync_array_size: 1024
max_connections: 16000
max_user_connections: 16000
table_definition_cache: 524288
table_open_cache: 524288
table_open_cache_instances: 64
The first sysvar jumps out and bites MySQL experts and anyone with basic knowledge of ACID-compliant MySQL configuration: innodb_flush_log_at_trx_commit = 0 disables durability on standard (open source) MySQL.
But Aurora is not MySQL.
Whether or not Aurora needs innodb_flush_log_at_trx_commit = 1 for ACID-compliant durability is, to my knowledge, not documented.
(Someday I’ll find out, but I don’t know right now.)
Given what Aurora has revealed about its storage system, my guess is that innodb_flush_log_at_trx_commit is not applicable to Aurora in the same way as standard MySQL.
Regardless, innodb_flush_log_at_trx_commit is one of the most important MySQL settings, so any benchmark that changes its default value (which is 1 for full ACID-complaint durability) should explicitly note and make clear how and why the change doesn’t fundamentally change the game.
innodb_sync_array_size is an interesting change, too.
But I’m not familiar with this sysvar or its impact on performance.
The default is 1 and the maximum is 1024.
If you search for it, two of the top results are post from AWS, but I can’t find independent expert advice on this sysvar (from Percona for example).
max_connections = 16000 is an interesting choice and nontrivial change, too.
16,000 is the maximum for any Aurora instance.
The benchmark creates 16,000 client connections, but I don’t think it’s reasonable or realistic.
It’s a rather common performance misconception that high throughput needs a lot of clients.
The other sysvars relate to open table caching, and all three are set to their maximum values. With only 250 tables in the benchmark, I don’t know why these maximum values are used. But that’s what you get when you peek behind the curtain: mysteries.
Looking for Answers in the Past
Upon writing this, I realize that it is perhaps weird that I look to the past for answers to this technical mystery. How could material from many years ago explain the errors and confusion of today? After all, technology changes, so past technology might be completely irrelevant to the problems of today.

But the present is only the tip of what we know. It doesn’t reveal the whole picture.

The more you understand the past…

the better you understand the present.
But where do we go from here? The Aurora white paper, “Amazon Aurora: Design considerations for high throughput cloud-native relational databases”, is a logical starting point because it was published in 2017. In that paper, section “6. PERFORMANCE RESULTS” begins to make more sense. For one thing, it’s written that r3.8xlarge EC2 instances are used, which matches the current Amazon FAQ statement: “Our tests with SysBench on r3.8xlarge instances…” The numbers are also inline with expectations: around 100,000 writes/second, not the red herring 200,000 QPS (INSERT/second) created by the 2019 technical guide.
We’re beginning to see the full picture. But the white paper doesn’t mention any details about the benchmark setup apart from instance class sizes and sysbench. We need those details…
Lucky for us, someone had the good idea to record revisions of the technical guide. On the last page of the 2019 technical guide we see “July 2015 First publication”. It stands to reason that the real and correct benchmark setup was published in 2015, then used for the 2017 white paper.
The Original 2015 Aurora Benchmark
It was remarkably difficult to unearth, but I found a copy: Amazon Aurora Performance Assessment (2015). And I’ve included it here so we can finally get to the bottom of the Aurora performance claims. I encourage you to read it because the benchmark setup is completely different than the 2019 revision:
- Aurora v1 vs. MySQL 5.6
- Database instance size: r3.8xlarge
- 30,000 provisioned IOPS io1 (RDS/MySQL)
- Default configuration (parameter group)
- sysbench v0.5
- 1 database
- 250 tables
- 25,000 rows per table
- Uniform random distribution
- 4 r3.8xlarge EC2 instances
- 4,000 connections (1k/EC2)
- MySQL and EC2 in same availability zone (AZ)
- 600 second (10 min.) runtime
This is a lot better! The database instance size is much smaller yet delivers the same performance: r3.8xlarge in 2015, not r4.16xlarge in 2019. And the sysbench setup and write-heavy workload are correct: 250 tables, each with 25,000 rows, and a mix of INSERT, UPDATE, and DELETE statements wrapped in a transaction. Whoever created and documented the 2015 Aurora benchmark: good work, and thank you.
Part b'11'
Catching the Rabbit
Recreating the original 2015 Aurora benchmark outline above (with a few modifications detailed below), I can confirm that the claim “100,000 UPDATEs/sec, five times higher than MySQL running the same benchmark on the same hardware” is true only with two points of clarification: it’s 100,000 writes/second (not updates/second), and MySQL is not tuned for the workload.
I know the first point of clarification is true and accurate for two reasons.
First, AWS wrote it in the 2015 technical guide (link above): “We ran this test for 600 seconds and observed a write performance of 101,386 write requests per second”.
Second, the sysbench OLTP write workload is 2 UPDATE, 1 DELETE, and 1 INSERT.
Update statements are only half the workload (slightly less counting BEGIN and COMMIT statements), so it cannot be 100k UPDATE/s if the total writes observed were 101,386 writes/s.
I’ll prove the second point of clarification is true in following sections.
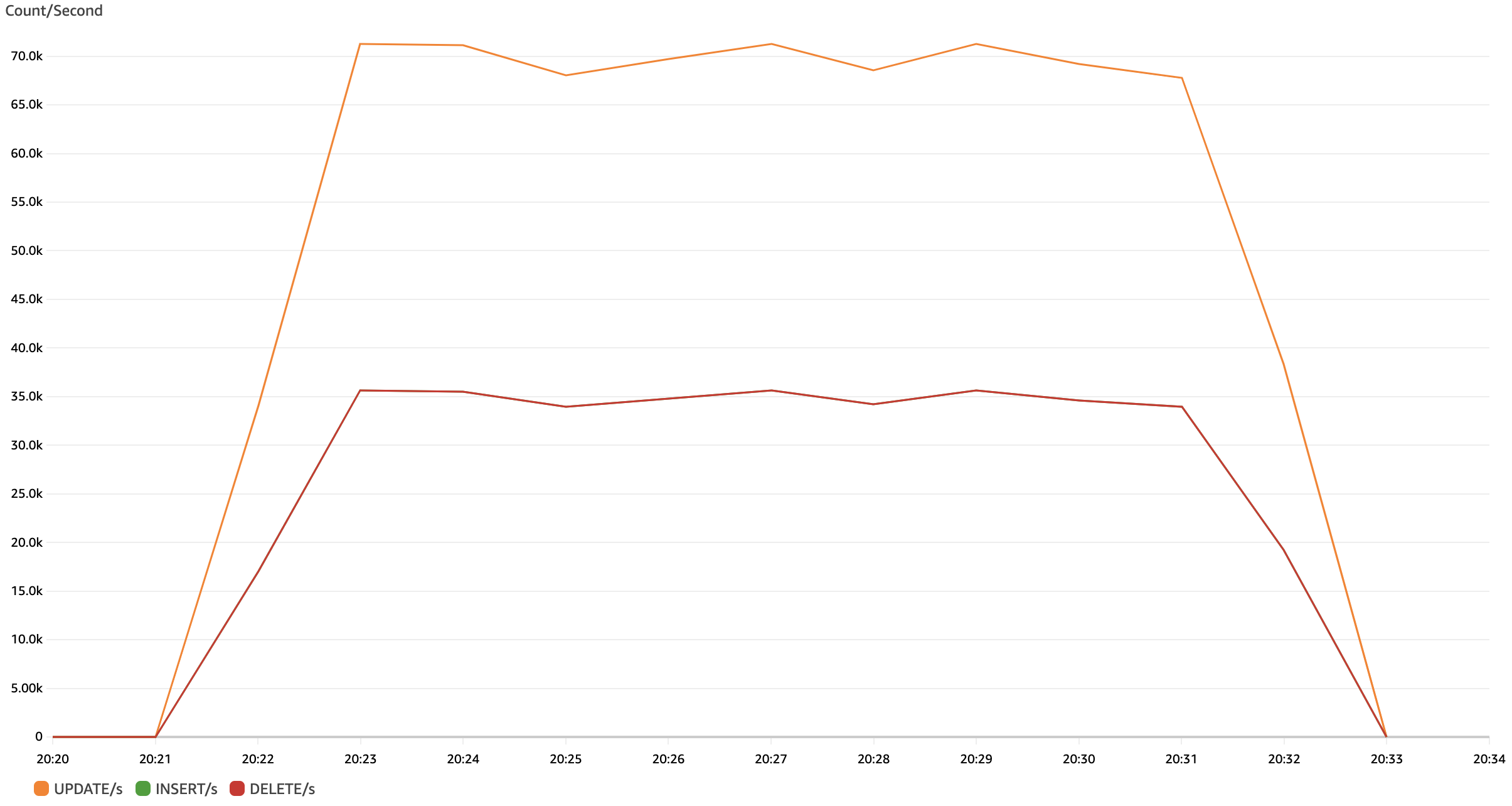
Chart 4: Aurora v2 INSERT, UPDATE, DELETE throughput on 2015 benchmark/2023 hardware
That chart above shows 140k writes/s on Aurora v2 for this benchmark:
- 70k UPDATE/s
- 35k DELETE/s
- 35k INSERT/s (hidden behind red line for DELETE/s)
Here are the numbers from each of my 4 EC2 instances that I’ll explain after.
runtime| clients| QPS| min| P95| max| r_QPS| r_min| r_P95| r_max| w_QPS| w_min| w_P95| w_max| TPS| c_min| c_P95| c_max| errors|compute
600| 1000| 53,142| 16| 72,443| 1,085,187| 0| 0| 0| 0| 35,428| 16| 23,988| 502,978| 8,856| 162| 93,350| 1,085,187| 0|ip-0000000000000.ec2.internal
600| 1000| 52,688| 14| 72,443| 1,080,313| 0| 0| 0| 0| 35,125| 14| 23,988| 967,351| 8,781| 1,109| 95,499| 1,080,313| 0|ip-000000000000.ec2.internal
600| 1000| 52,127| 30| 72,443| 1,079,020| 0| 0| 0| 0| 34,751| 46| 23,988| 810,917| 8,687| 1,960| 95,499| 1,079,020| 0|ip-0000000000000.ec2.internal
600| 1000| 52,249| 24| 72,443| 1,078,195| 0| 0| 0| 0| 34,833| 24| 23,988| 621,627| 8,708| 2,346| 95,499| 1,078,195| 0|local
600| 4000| 210,207| 14| 72,443| 1,085,187| 0| 0| 0| 0| 140,138| 14| 23,988| 967,351| 35,034| 162| 95,499| 1,085,187| 0|(4 combined)
Table 1: Aurora v2 stats on 2015 benchmark/2023 hardware
Each line of the output is stats from a single compute (EC2) instance and its clients (MySQL connections). The last line is the combined stats of all compute, done correctly: min of all the min, max of all the max, histogram buckets combined for percentiles, etc. All time values are in microseconds (μs): 16=16μs, 72,443=72.4ms, 1,085,187 = 1.1s, etc. The columns, left to right, are:
runtime: Runtime in secondclients: Number of MySQL clients (connections)QPS: Total queries per secondmin: Minimum query response timeP95: 95th percentile query response timemax: Maximum query response timer_*: Same as previous four columns but only reads (SELECT)w_*: Same asr_*but only writes (not COMMIT)TPS: Same asr_*but only COMMITerrors: Error countcompute: Compute hostname or “(N combined)” for all compute stats combined
We’re looking at w_QPS: writes per second (not including COMMIT).
The second part of the Aurora claim is “5X greater than standard open source MySQL on similar hardware.” Is that true? Yes it is, but again: MySQL is not tuned for the workload. Since AWS does not provide the same metrics/charts for RDS as Aurora, I don’t have a similar chart, just the raw numbers for this benchmark on MySQL 5.7:
runtime| clients| QPS| min| P95| max| r_QPS| r_min| r_P95| r_max| w_QPS| w_min| w_P95| w_max| TPS| c_min| c_P95| c_max| errors|compute
600| 1000| 7,122| 405| 120,226| 21,229,160| 0| 0| 0| 0| 4,748| 457| 229,086| 21,229,160| 1,186| 1,996| 52,480| 841,176| 0|ip-0000000000000.ec2.internal
600| 1000| 7,175| 347| 120,226| 21,445,907| 0| 0| 0| 0| 4,784| 402| 229,086| 21,445,907| 1,194| 1,982| 52,480| 852,829| 0|ip-000000000000.ec2.internal
600| 1000| 7,200| 341| 120,226| 21,405,843| 0| 0| 0| 0| 4,800| 394| 218,776| 21,405,843| 1,198| 1,812| 52,480| 941,664| 0|ip-0000000000000.ec2.internal
600| 1000| 7,157| 402| 120,226| 21,254,657| 0| 0| 0| 0| 4,772| 460| 229,086| 21,254,657| 1,191| 1,895| 52,480| 984,411| 0|local
600| 4000| 28,656| 341| 120,226| 21,445,907| 0| 0| 0| 0| 19,105| 394| 229,086| 21,445,907| 4,771| 1,812| 52,480| 984,411| 0|(4 combined)
Table 2: RDS MySQL 5.7 stats on 2015 benchmark/2023 hardware
Aurora v2 140,138 writes/s versus MySQL 5.7 19,105 writes/s: Aurora is 7.3X faster in this case—under these specific conditions.
Speaking of which, a lot has change from 2015 to 2023, so I had to update three conditions of the benchmark:
| 2015 | 2023 |
|---|---|
| Aurora v1 vs. MysQL 5.6 | Aurora v2.11.2 vs. MySQL 5.7.41 |
| r3.8xlarge | r5.8xlarge |
| sysbench v0.5 | Finch |
| No binlogs? | No binlogs |
| Multi-AZ? | Multi-AZ |
| Encrypted? | Encrypted at rest |
None of these changes are material to the outcome; we’re still comparing the same benchmark on the same hardware, just Aurora vs. MySQL. If anything, the changes show that MySQL 5.7 is faster than 5.6, as is AWS r5 vs. r3—both of which we’d expect.
Bigger! Faster! Hardware!
There are several ideas and themes threaded throughout Efficient MySQL Performance. One is the fallacy of assuming that bigger, faster hardware will fix slow performance. I use the word “assume” (not “presume”) because it’s accurate: engineers assume, without good reasons, that bigger faster hardware is a solution. This fallacy is difficult to demonstrate, but we have the opportunity here, so let’s take it.
Does doubling the MySQL instance size from r5.8xlarge to r5.16xlarge boost its performance?
runtime| clients| QPS| min| P95| max| r_QPS| r_min| r_P95| r_max| w_QPS| w_min| w_P95| w_max| TPS| c_min| c_P95| c_max| errors|compute
600| 1000| 5,521| 91| 263,026| 22,287,183| 0| 0| 0| 0| 3,681| 139| 501,187| 22,287,183| 919| 2,340| 114,815| 4,090,852| 0|ip-0000000000000.ec2.internal
600| 1000| 5,493| 105| 263,026| 21,684,267| 0| 0| 0| 0| 3,662| 147| 501,187| 21,684,267| 914| 1,946| 114,815| 4,036,877| 0|ip-000000000000.ec2.internal
600| 1000| 5,505| 109| 263,026| 23,415,984| 0| 0| 0| 0| 3,670| 142| 501,187| 23,415,984| 916| 2,079| 114,815| 4,081,525| 0|ip-0000000000000.ec2.internal
600| 1000| 5,497| 104| 263,026| 21,697,550| 0| 0| 0| 0| 3,665| 142| 501,187| 21,697,550| 915| 1,915| 114,815| 4,076,611| 0|local
600| 4000| 22,017| 91| 263,026| 23,415,984| 0| 0| 0| 0| 14,679| 139| 501,187| 23,415,984| 3,666| 1,915| 114,815| 4,090,852| 0|(4 combined)
Table 3: RDS MySQL 5.7 stats on 2015 benchmark/2023 hardware but r5.16xlarge
Worse performance!? But we doubled the hardware!
I know it’s difficult for some engineers to believe, but the numbers don’t lie (and I didn’t mess up the benchmark; I show results once, but I ran every benchmark several times). With twice the hardware, write throughput decreased by 23%: 19,105 → 14,679.
First of all, RDS for MySQL stores data on EBS volumes in multiple AZs. EBS latency is highly variable; see COMMIT Latency: Aurora vs. RDS MySQL 8.0. Over many days and countless benchmark runs, RDS write performance (throughput and latency) varied highly. Sometimes it would push 19k writes/s, then 14k writes/s immediately after, then back to 18k writes/s later or the next day. This seems to be normal for EBS.
Second of all, what does doubling the database instance size give us?
| Instance | CPU | RAM | EBS | Network |
|---|---|---|---|---|
| 8xlarge | 32 | 256 | 6,800 Mbps | 10 Gbps |
| 16xlarge | 64 | 512 | 13,600 Mbps | 20 Gbps |
But are any of those a bottleneck? Unlikely because Aurora has the same 8xlarge limits. Sometimes extra “horsepower” hurts more than it helps because it overloads an already overloaded system.
There it is: proof positive that bigger, faster hardware does not solve all performance issues.
Deep
The bottleneck is EBS: network-backed storage has millisecond latency. That’s equivalent to spinning disks, even though the storage uses SSD. And those 30,000 provisioned IOPS? Worthless—wasted money—in this case because write I/O for MySQL is ultimately serialized into the redo logs—and binary logs, if they’re enabled, which they’re not for this benchmark. Check out InnoDB Page Flushing Diagram for the high-level (but incomplete) flow of write I/O in MySQL from transaction commit.
Since reads are supposed to be served from the buffer pool and the buffer pool is kept in memory, it's common to associate IOPS with writes, but checkout MySQL IOPS for Reads and Surprsies. IOPS are used for reads, too, which might justify a high number of IOPS for RDS.
If you're thinking "Increase innodb_io_capacity and innodb_io_capacity_max to match the provisioned IOPS," that's a good idea but it doesn't help. Storage latency is the issue; read Understanding Storage Performance - IOPS and Latency to learn more.
Aurora I/O is totally different. In addition to the Aurora white paper linked earlier, check out these videos:
- AWS re:Invent 2020: Amazon Aurora storage demystified
- AWS re:Invent 2021 - Deep dive on Amazon Aurora
Aurora doesn’t have a redo log like MySQL. So when we’re hammering it with writes, we don’t need to think much about the write path: how the data changes will sync and flush to disk through a redo log on network-backed storage.
But when we’re hammering MySQL with writes, we do need to think about the write path and probably tune its configuration. That’s not always easy, but here’s why it’s worth it:
runtime| clients| QPS| min| P95| max| r_QPS| r_min| r_P95| r_max| w_QPS| w_min| w_P95| w_max| TPS| c_min| c_P95| c_max| errors|compute
600| 1000| 31,201| 28| 83,176| 8,049,759| 0| 0| 0| 0| 20,801| 37| 95,499| 8,049,759| 5,199| 28| 43,651| 920,814| 0|ip-0000000000000.ec2.internal
600| 1000| 30,995| 31| 83,176| 8,193,389| 0| 0| 0| 0| 20,664| 44| 95,499| 8,193,389| 5,165| 31| 43,651| 907,150| 0|ip-000000000000.ec2.internal
600| 1000| 31,201| 29| 83,176| 8,379,938| 0| 0| 0| 0| 20,801| 29| 95,499| 8,379,938| 5,199| 758| 43,651| 878,295| 0|ip-0000000000000.ec2.internal
600| 1000| 31,127| 33| 83,176| 7,836,409| 0| 0| 0| 0| 20,751| 33| 95,499| 7,836,409| 5,186| 312| 43,651| 862,860| 0|local
600| 4000| 124,526| 28| 83,176| 8,379,938| 0| 0| 0| 0| 83,018| 29| 95,499| 8,379,938| 20,750| 28| 43,651| 920,814| 0|(4 combined)
Table 4: RDS MySQL 5.7 stats on 2015 benchmark/2023 hardware (r5.8xlarge) and 1 GB log file
MySQL write throughput increased 334%: 19,105 → 83,018 writes/s.
Now Aurora is only 1.7x faster than MySQL on the same hardware and benchmark.
The configuration change was simple: I increased innodb_log_file_size from the RDS default of 128 MB to 1 GB.
(There two log files by default, so the total log size is double this value.)
A write-only benchmark puts pressure on the redo log, so a larger log helps reduce “furious flushing” by giving MySQL more space to buffer data changes between checkpoints.
And if you watched the two videos linked above, you know that Aurora checkpointing is also completely different than MySQL.
MySQL might not sustain this level of performance for a longer run (this benchmark is only 10 minutes), and EBS latency varies significantly. For example, I ran the benchmark again (immediately after the run shown above) and it yielded only a 276% increase: 71,911 writes/s. And then again for a 331% increase (82,517 writes/s). Despite variations, these results prove that Aurora is not 5X faster than MySQL when MySQL is properly configured for the benchmark.
IOPS, storage latency, redo logs, checkpoints, flushing… these deep technical considerations (and many more) explain why “the truth” in database performance is usually not a simple matter that can be fairly or accurately captured by marketing.
The Truth
Not all truths are useful. The true fact that I’m sitting in a chair while I write this… so what? Prima facie, the Aurora 5X performance claim is no more useful than that. You must—I repeat: you must—determine if your database conditions are similar to the conditions on which the claim is made. Only then can you gauge its usefulness.
For non-engineers reading this who can’t determine and test those conditions, I can tell you that in my experience and benchmarks, Aurora is usually—but not always—faster than MySQL. I’ve spent a lot of time trying to make MySQL beat Aurora, but I don’t think it’s possible because it’s not a fair fight: MySQL comes from the era of single servers and spinning disks; Aurora was purpose-built for where it runs: the cloud. If you’re born and raised in the desert, you might learn to surf pretty well, but you’re probably not going to beat your friends from Santa Cruz.
And just when you think you’ve got a handle on all this performance stuff, Amazon RDS Optimized Writes enables up to 2x higher write throughput at no additional cost: the rabbit hole goes deeper.
Copyright 2025 Daniel Nichter